I have ADHD. I’ve mentioned this before. My AI agent also has ADHD — not by design, but because every MCP-compatible agent starts each session with the memory of a goldfish.
Every morning I’d open Claude Code and repeat myself. “I use TypeScript.” “Tests are in vitest.” “Don’t push to origin from the KB repo.” “My name is Nikita, not ‘the user.’” By the third week I was spending more time re-teaching my agent than actually coding.
Something had to give. So I built mnemon-mcp — a persistent memory server that gives any MCP client structured long-term recall. One SQLite file, zero cloud, nothing leaves your machine.
Here’s what I learned building it.
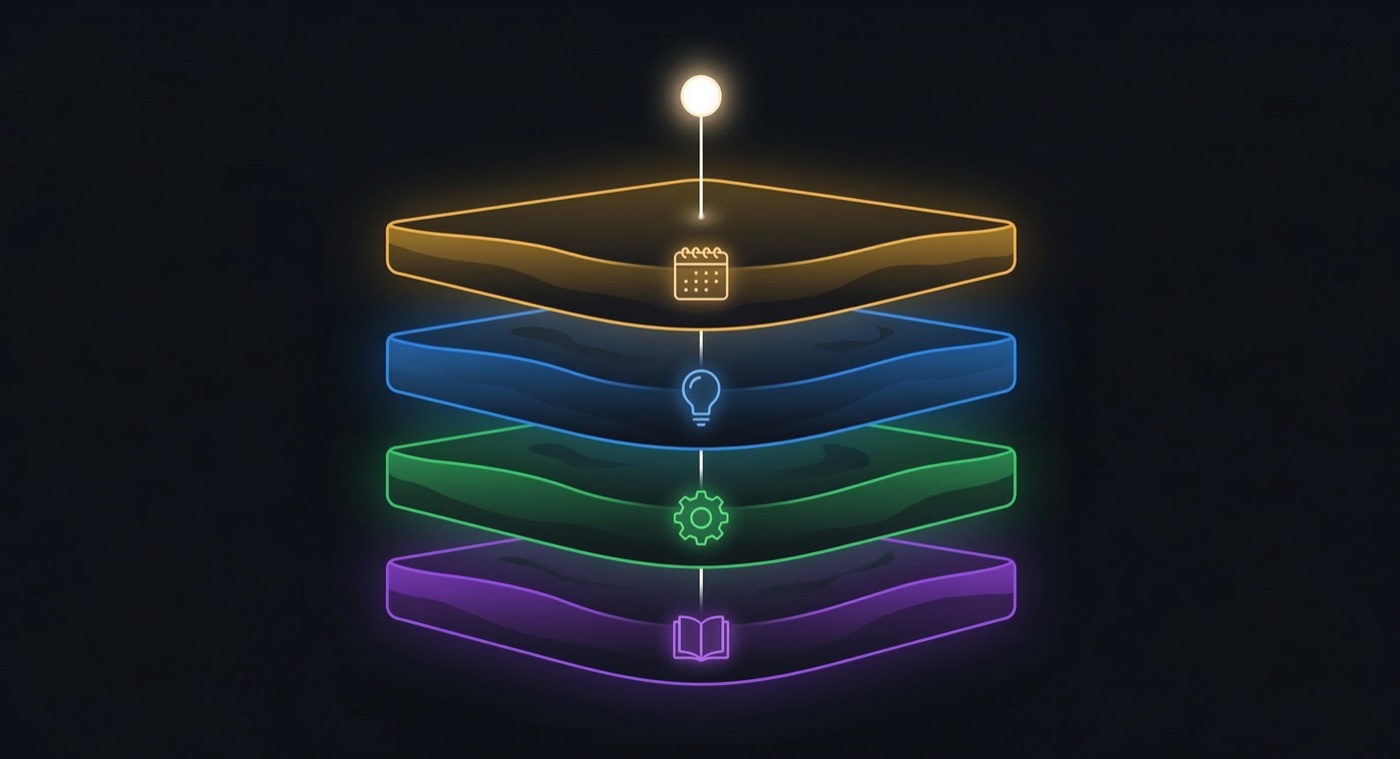
Table of contents
Open Table of contents
The Problem Nobody Talks About
Every AI agent framework has a memory story. Most of them are bad.
The standard approach: dump everything into a vector database and pray that cosine similarity finds the right context. Or worse — a flat JSON file that grows until the model’s context window chokes on it.
I tried three existing solutions before giving up:
| Solution | What went wrong |
|---|---|
| Flat JSON memory | 800 entries, 60% irrelevant noise in every context load |
| Cloud memory service | $19/month to store MY data on SOMEONE ELSE’s server |
| Vector-only search | ”Never push without tests” matched “unit tests for push notifications” |
The fundamental issue: not all knowledge is the same kind of knowledge.
“I debugged auth on March 5” is an event — it should fade. “Never push without tests” is a rule — it should never fade. “My teammate’s name is Zhenya” is a fact — it should be stable until corrected. “Summary of Clean Code Chapter 3” is a reference — you pull it when you need it.
Dumping all four into one bucket and hoping search figures it out is like storing your diary, your address book, your shopping list, and your bookshelf in one pile on the floor. It works until it doesn’t. For me, it stopped working around entry 200.
The Insight: Memory Has Layers
The human brain doesn’t store everything the same way. Episodic memory (what happened), semantic memory (what you know), and procedural memory (how to do things) are distinct systems with different access patterns and decay rates.
I borrowed that model and added a fourth layer for reference material:
| Layer | What it stores | How it’s accessed | Lifetime |
|---|---|---|---|
| Episodic | Events, sessions, journal entries | By date or period | Decays (30-day half-life) |
| Semantic | Facts, preferences, relationships | By topic or entity | Stable |
| Procedural | Rules, workflows, conventions | Loaded at startup | Rarely changes |
| Resource | Book notes, reference material | On demand | Decays slowly (90 days) |
This isn’t a new idea. Cognitive science has known this for decades. But somehow every AI memory system I found was either flat (one bucket) or graph-based (everything relates to everything, good luck searching).
What I Actually Built
mnemon-mcp is an MCP server. It speaks JSON-RPC over stdio. Any MCP-compatible client — OpenClaw, Claude Code, Cursor, Windsurf — connects to it and gets 7 tools:
| Tool | What it does |
|---|---|
memory_add | Store a memory with layer, entity, confidence, importance |
memory_search | Full-text search with filters by layer, entity, date, scope |
memory_update | Update in-place or create a versioned replacement |
memory_delete | Delete a memory; re-activates predecessor if part of a chain |
memory_inspect | Layer statistics or single memory history trace |
memory_export | Export to JSON, Markdown, or Claude-md |
memory_health | Diagnostics and optional garbage collection |
The backend is SQLite with FTS5. No Postgres. No Redis. No Docker. One file at ~/.mnemon-mcp/memory.db that you can back up by copying it.
npm install -g mnemon-mcpThat’s the whole setup. I spent three months building it so you could spend 10 seconds installing it. The ROI math doesn’t work out, but I have ADHD — we don’t do ROI math.
Fact Versioning
Knowledge changes. Your team migrated from React 17 to React 19. You don’t want to delete “team uses React 17” — that might be useful context later. You want to chain them:
v1: "Team uses React 17" → superseded_by: v2
v2: "Team uses React 19" → supersedes: v1 (active)Search returns only the latest version. memory_inspect reveals the full chain. memory_delete re-activates the predecessor. Nothing is lost.
This turns out to be important more often than you’d think. An agent correcting a fact isn’t the same as an agent deleting one.
Stemming: Because Languages Are Hard
I write code in English and everything else in Russian. So the search engine needed to handle both.
Snowball stemmer at both index time and query time: "running" matches "runs", and "книги" matches "книга". Stop words filtered in both languages.
Getting Russian morphology right in FTS5 was one of those problems that sounds trivial and isn’t. Russian has 6 grammatical cases, 3 genders, and diminutive forms that change the stem entirely. Snowball handles 90% of it. The other 10% is why I drink tea at 2 AM on Phangan while staring at a regex.
The Tuning Saga: 36.9 → 70.5
I built an eval framework with 50 golden test cases — real queries against real memories. Measured Recall@5, MRR, and nDCG@5.
First score: 36.9 out of 100.
That’s not “needs improvement.” That’s “your search engine is actively guessing.”
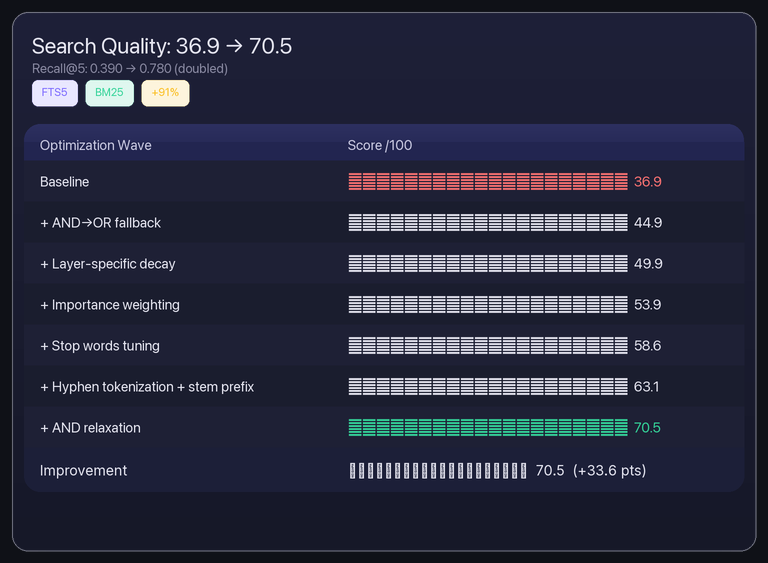
| Change | Impact |
|---|---|
| AND → OR fallback when AND returns too few results | +8 pts |
| Decay only for episodic/resource (not semantic/procedural) | +5 pts |
Importance weighting: 0.3 + 0.7 × importance | +4 pts |
| Stop words: removed “серия” forms killing habit queries | +3 pts |
| Hyphen tokenization: “рэп-архив” → two tokens | +2 pts |
| Stem prefix minimum: 3→2 chars (fixes “Юле”→“юл”) | +2 pts |
| Progressive AND relaxation: top-3 longest stems first | +1.5 pts |
Final score: 70.5 out of 100. Recall@5 went from 0.390 to 0.780 — doubled.
The remaining 9 failures are mostly temporal queries (“what happened last week?”) that need date-aware search I haven’t built yet. PRs welcome.
What FTS5 Taught Me
Every one of these was counterintuitive:
BM25 scores are corpus-dependent. When I deleted superseded entries from the index, the remaining entries’ scores shifted because the statistical background changed. So I kept superseded entries in the FTS index as “dead” documents for stability. My search index intentionally contains stale data. This is correct.
OR is a terrible default. AND first, OR as supplement when AND returns too few results, at a 0.9x score penalty. Three rewrites to learn what sounds obvious in retrospect.
Access count = popularity bias. My first version boosted frequently accessed memories. On a single-user KB, that creates a feedback loop — popular memories get more popular. Removed it.
Decay is layer-dependent. Applying time decay to “never push without tests” killed factual recall. Decay applies to events and references. Facts and rules don’t expire because Tuesday was two weeks ago.
What I Got Wrong
1. I built search before import. The import pipeline was an afterthought. It should have been designed first — the shape of your data determines your search quality. Rebuilt it twice.
2. I ignored snippets. FTS5 has a snippet() function for highlighted results. But since I index stemmed content, snippets return stems instead of words. “книг” instead of “книги”. Shipped it broken. It haunts me.
3. I over-engineered scoring. First version: frequency boosts, recency bonuses, confidence multiplier. Final version: bm25 × (0.3 + 0.7 × importance) × decay(layer). Simpler is always better. Every time.
4. 268 memories is not 10,000. My eval results look good at current scale. I have no idea how this performs at 10K entries. If you import 10K memories and everything breaks, I want to know.
How It Compares
| mnemon-mcp | mem0 | basic-memory | |
|---|---|---|---|
| Architecture | SQLite FTS5 | Cloud + Qdrant | Markdown + vector |
| Memory structure | 4 typed layers | Flat | Flat |
| Fact versioning | Superseding chains | Partial | No |
| Stemming | EN + RU | EN only | EN only |
| Cloud required | No | Yes | No |
| Cost | Free | $19–249/mo | Free |
| Setup | npm install -g | Docker + API keys | pip + deps |
Try It
npm install -g mnemon-mcpAdd to your MCP client config:
{
"mcpServers": {
"mnemon-mcp": {
"command": "mnemon-mcp"
}
}
}Your agent now remembers.
- Landing page: aisatisfy.me/mnemon
- npm: mnemon-mcp on npm
- GitHub: nikitacometa/mnemon-mcp
MIT licensed. 4 production dependencies. 182 tests. Works everywhere Node 22+ runs.
If you use it, break it, or hate it — open an issue. The best bug reports come from people who actually needed the thing to work.
This post was written in Claude Code, which uses mnemon-mcp as its memory server. The agent that wrote it remembered my writing style, my ADHD references, and the fact that I live on Phangan — without being told. That’s the whole point.